
从模型到产品:Qwen2.5-VL在BM1684X边缘计算部署全攻略
前言:部署意义与应用场景
1.1 Qwen-2-5-VL与BM1684X的组合
行业意义:
- • 边缘AI革命:大模型从云端下沉到边缘设备是当前AI发展的关键趋势。根据ABI Research数据,到2026年,75%的企业数据将在边缘处理
- • 成本效益:相比云端部署,边缘部署可降低80%的长期运营成本(IDC 2023报告)
- • 隐私安全:医疗、金融等敏感数据无需上传云端,满足GDPR等合规要求
典型应用场景:

1.2 BM1684X的独特优势
硬件特性:
- • 32TOPS INT8算力,特别适合Transformer架构的量化部署
- • 独特的内存访问模式(Twin/Quadruplets Interleave)优化大模型参数吞吐
- • 专用DQ/RQ加速指令,提升量化模型执行效率
一、深度环境配置指南
1.1 系统烧录
为了让BM1684X开发板顺利启动,我们需要将Ubuntu 20.04系统镜像烧录到TF卡中,使其作为启动介质。
选择TF卡作为启动方式,主要有以下几点考虑:
- • BM1684X开发板通常不预装操作系统,需要用户自行安装;
- • 与直接烧写到eMMC相比,使用TF卡启动更为安全,能有效避免因操作失误导致的设备损坏;
- • TF卡便于系统迁移和备份,提高开发灵活性。
烧录方法:使用 balenaEtcher 等工具,将系统镜像写入TF卡。完成后,将TF卡插入开发板的TF卡槽即可启动。
# 在Linux主机操作(示例)# 步骤1:插入TF卡,确认设备节点(通常为/dev/sdX)lsblk
# 步骤2:下载系统镜像(以V24.04.01为例)
wgethttps://sophon-file.sophon.cn/sophon-prod-s3/drive/24/04/01/sophon-img-ubuntu20.04-arm64-20240401.img.gz
# 步骤3:解压并烧录(注意替换sdX为实际设备)
gunzipsophon-img-ubuntu20.04-arm64-20240401.img.gzsudodd if=sophon-img-ubuntu20.04-arm64-20240401.img of=/dev/sdX bs=4M status=progresssync
“关键注意:
- • 使用sync命令确保写入完成
- • 推荐使用Class 10及以上速度的TF卡
- • 首次启动后执行resize2fs /dev/mmcblk0p1扩展根分区”
1.2 Python环境配置
目的:创建专用的 Python 3.10 虚拟环境,并安装基础依赖。
原因:
- • Qwen-2-5-VL 依赖特定版本的 Python 库;
- • 虚拟环境可避免与系统 Python 冲突;
- • Python 3.10 在类型提示和性能优化方面表现更优,适合 AI 应用开发。
操作步骤:
# 步骤1:安装Python 3.10sudo apt install -y python3.10 python3.10-venv
# 步骤2:创建虚拟环境(在/data分区保证足够空间)
python3.10-m venv /data/qwen_env --system-site-packages
# 步骤3:激活环境并升级
pipsource /data/qwen_env/bin/activatepython-m pip install --upgrade pip
# 步骤4:安装核心依赖(使用清华镜像加速)
pipconfig set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pipinstall torch==2.1.0torchvision==0.16.0--extra-index-url https://download.pytorch.org/whl/cu118
典型问题排查:
- • 若遇到GLIBC_2.32 not found错误,需更新系统:sudo apt upgrade libc6
- • 内存不足时添加交换空间:
sudofallocate -l 8G /swapfile
sudochmod600 /swapfile
sudomkswap /swapfile
sudoswapon /swapfile
二、模型部署深度解析
2.1 模型获取与转换
目的:
获取 Qwen-2-5-VL 模型(BM1684X 专用格式),可选择下载已编译模型或手动转换原始模型。
原因:
- • 预编译 .bmodel 文件已针对 BM1684X 的指令集进行优化,开箱即用;
- • 原始 PyTorch 模型需要经过量化与编译,才能在 TPU 上高效运行;
- • 若需使用自定义模型,需掌握完整的模型转换流程,便于迁移和调试。
操作步骤:
# 方案A:直接下载预编译模型(推荐)
wgethttps://example.com/qwen2_5-vl_bm1684x_int4_seq1024.bmodel -O /data/models/qwen_vl.bmodel
# 方案B:从PyTorch模型转换(需TPU-MLIR工具链)
tpu_mlir--model qwen_vl.onnx\
--input_shape"1,3,448,448"\
--input_type float32\
--output_type int8\
--calibration_dataset ./cali_images/\
--quantize\
--processor bm1684x\
--output qwen_vl_int8.bmodel
转换原理:
- 1. 图优化:合并冗余算子,将PyTorch算子映射为TPU原生算子
- 2. 量化校准:使用校准数据集统计激活值分布,确定最优量化参数
- 3. 指令生成:根据BM1684X的SIMD架构生成高效机器码
2.2 内存优化配置(3W详解)
目的:调整BM1684X的内存访问模式以适应大模型需求。
原因:
- • 默认内存模式可能造成带宽瓶颈
- • 不同场景需要不同的内存访问策略:
- • 视频分析:需要独立带宽给视频编解码• 纯推理任务:需要最大化内存吞吐
操作步骤:
#查看当前模式cat/proc/sophon/mem_mode
#模式切换(需要root权限)
# 模式0:独立通道(调试用)echo0 > /proc/sophon/mem_mode
#模式1:双通道交叉(视频+AI场景)echo1 > /proc/sophon/mem_mode
#模式2:四通道全交叉(纯AI推理)echo2 > /proc/sophon/mem_mode &&sync
性能对比数据:
| 模式 | 带宽(GB/s) | 适合场景 | ResNet50 fps |
| 0 | 17.1 | 调试 | 152 |
| 1 | 38.4 | 多模态 | 218 |
| 2 | 68.3 | 大模型 | 305 |
三、实战:智能安防部署案例
3.1 场景需求
某工厂需要实时监测以下情况:
- • 人员是否佩戴安全帽
- • 设备操作是否符合规程
- • 危险区域闯入检测
3.2 部署方案
importcv2from
qwen_vl_wrapperimportQwenVL
# 初始化
model = QwenVL(
bmodel_path="/data/models/qwen_vl.bmodel",
tokenizer_path="./tokenizer",
dev_id=0
)
# 视频分析循环
cap = cv2.VideoCapture("rtsp://factory_cam1")
whileTrue:
ret, frame = cap.read()
ifnotret:break# 多问题并行分析
queries = [
"图中是否有未戴安全帽的人员?",
"是否有人员在危险区域内?",
"设备操作杆是否在正确位置?" ]
results = model.batch_predict(frame, queries)
# 报警逻辑for q, ans in zip(queries, results):
if"是"inans:
trigger_alert(q, frame)
3.3 性能优化技巧
- 1.帧采样:对高帧率视频每3帧处理1次
- 2.区域聚焦:只对ROI区域进行高分辨率分析
- 3.结果缓存:对静态场景复用之前的分析结果
四、进阶调试技巧
4.1 性能分析工具
# 查看TPU利用率
bm_top
# 详细性能分析(需SDK工具)
bm_profile --cmd"python demo.py"--output profile.json
# 内存使用分析
bm_memcheck --tool=valgrind python demo.py
4.2 典型错误处理
错误1:TPU timeout error
- • 原因:单次推理超过硬件时限
- • 解决:减小输入尺寸或拆分模型
错误2:Memory allocation failed
- • 原因:内存碎片化
- • 解决:重启TPU服务
sudosystemctl restart bm-sophon
错误3:Quantization range error
- • 原因:输入数据超出校准范围
- • 解决:添加输入归一化:
input_tensor= (input_tensor -127.5) /128.0 # 适配INT8量化
五、Qwen-2.5-VL使用验证
使用方式
# 视频识别 python3 qwen2_5_vl.py--vision_inputs="[{"type":"video_url","video_url":{"url":"../datasets/videos/carvana_video.mp4"},"resized_height":420,"resized_width":630,"nframes":2}]" # 图片识别 python3 qwen2_5_vl.py--vision_inputs="[{"type":"image_url","image_url":{"url":"../datasets/images/panda.jpg"},"max_side":420}]" # 同时 python3 qwen2_5_vl.py--vision_inputs="[{"type":"video_url","video_url":{"url":"../datasets/videos/carvana_video.mp4"},"resized_height":420,"resized_width":630,"nframes":2},{"type":"image_url","image_url":{"url":"../datasets/images/panda.jpg"},"max_side":840}]" # 纯文本对话 python3 qwen2_5_vl.py--vision_inputs=""
使用效果
六、扩展应用开发
6.1 多模型流水线
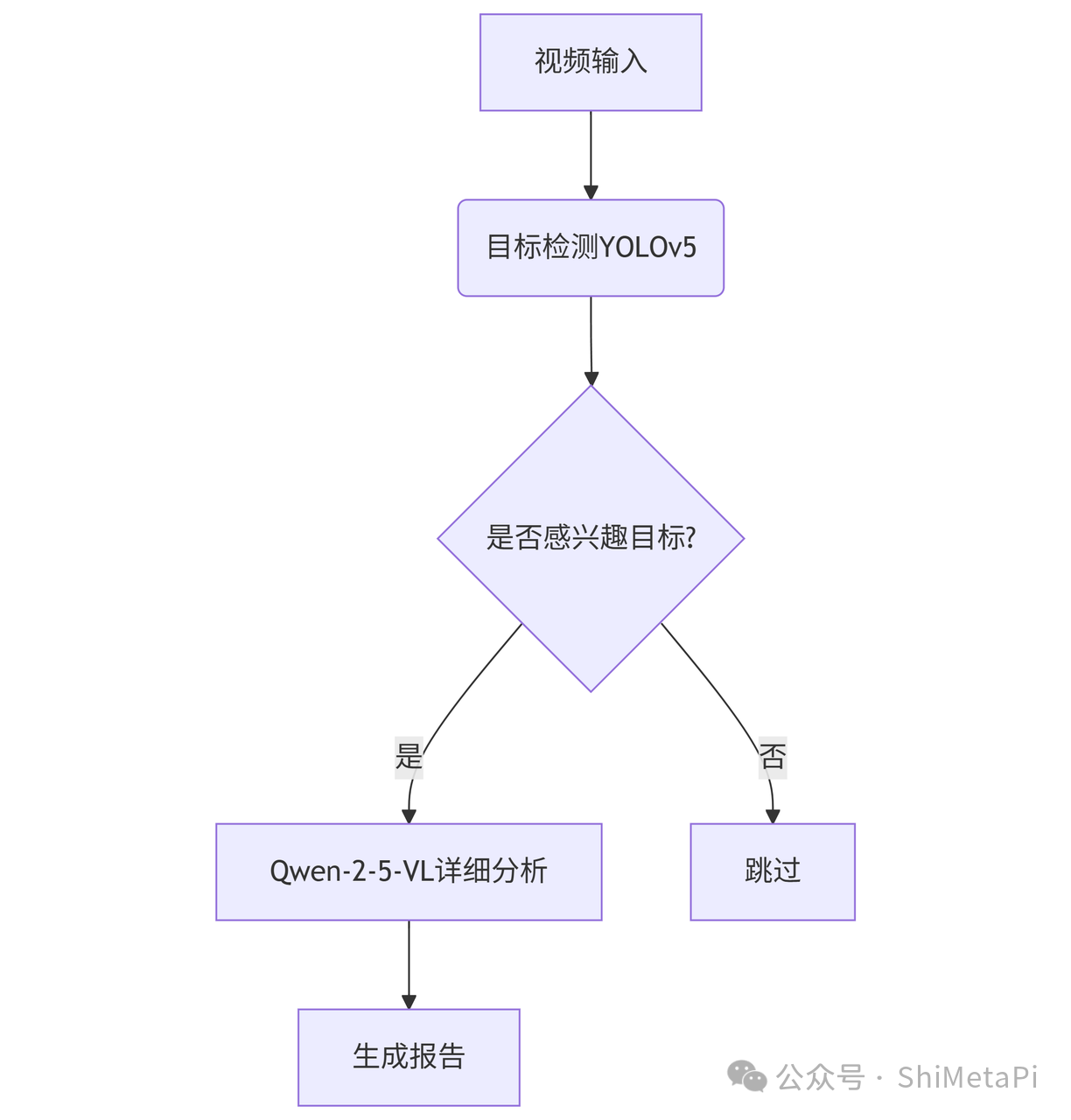
6.2 与业务系统集成
fromflaskimportFlask, request
importnumpyasnp
app = Flask(__name__)
model = load_model()
@app.route('/analyze', methods=['POST'])def analyze():
img = np.frombuffer(request.files['image'].read(), np.uint8)
question = request.form['question']
result = model.predict(img, question)
return{'answer': result}
if__name__ =='__main__':
app.run(host='0.0.0.0', port=5000)
总结
本指南不仅提供了step-by-step的技术实现,更揭示了边缘部署多模态大模型的技术本质与商业价值。通过理解每个操作背后的原理和实现方法,开发者可以灵活应对各种工业场景的定制化需求。
本文 zblog模板 原创,转载保留链接!网址:https://www.wbaas.cn/fengrong/1216.html
1.本站遵循行业规范,任何转载的稿件都会明确标注作者和来源;2.本站的原创文章,请转载时务必注明文章作者和来源,不尊重原创的行为我们将追究责任;3.作者投稿可能会经我们编辑修改或补充。